The Silo on My Laptop
Every week, I hear about a new app someone on my team is working on, including RFP prep, roadmap planning, product QA bots, strategy research… and the list grows.
The same is true for our customers in life sciences, where they’re enabling IT and scientists to vibe code some of their own solutions. At some point not long ago, that term “vibe code” carried a negative connotation, as if it was somehow less than applications built sans vibe and with blood, sweat, and tears instead. That sentiment is starting to feel increasingly silly.
I’ll give you a very practical example. Two weeks ago, I set out to build Portfolio Nexus, an internal TypeScript + Next.js + Supabase portfolio tracking app, affectionately named after the Nexus in Star Trek Generations. It’s beautiful, well architected, well tested (supposedly), and brings together views that I know will help us plan more effectively. After sending a few colleagues my internal VPN IP to access my locally hosted app, and then again as my IP kept changing, I quickly and obviously realized this type of “deployment” wasn’t going to cut it.
To further complicate the situation, a colleague of mine in parallel was building an app to collect the next level of detail – epics, team assignments, etc. via MCP to Jira. The data in his app would materially make the data in mine more grounded in relevant specifics. But he also had his app locally hosted. Cue the data silo story. More on that later.
Here’s the broader point: the amount of software will increase, and SaaS won’t die as a result. As software creation becomes cheap and widespread, the strategic value of software platforms will grow from helping people build software to providing the governed data, context, and domain intelligence that make all that newly created software useful. The data community learned this lesson years ago. It’s why the FAIR principles (Findable, Accessible, Interoperable, Reusable) became essential as data proliferated. We’re about to need the same thinking for apps.
The World Is Still Short Software
I’m not the only one noticing this.
In a recent piece titled Good News: AI Will Eat Application Software, a16z argues that the current panic is based on a fundamental misunderstanding of what software companies actually sell.
“AI simply isn’t going to kill software companies. After all this panic has passed, we’ll see that AI is the best thing that ever happened to the software industry.”
This is a contrarian take. The market consensus right now is that AI is going to kill the software industry, and investors have acted accordingly. Software ETFs have fallen 30% since the start of 2026.
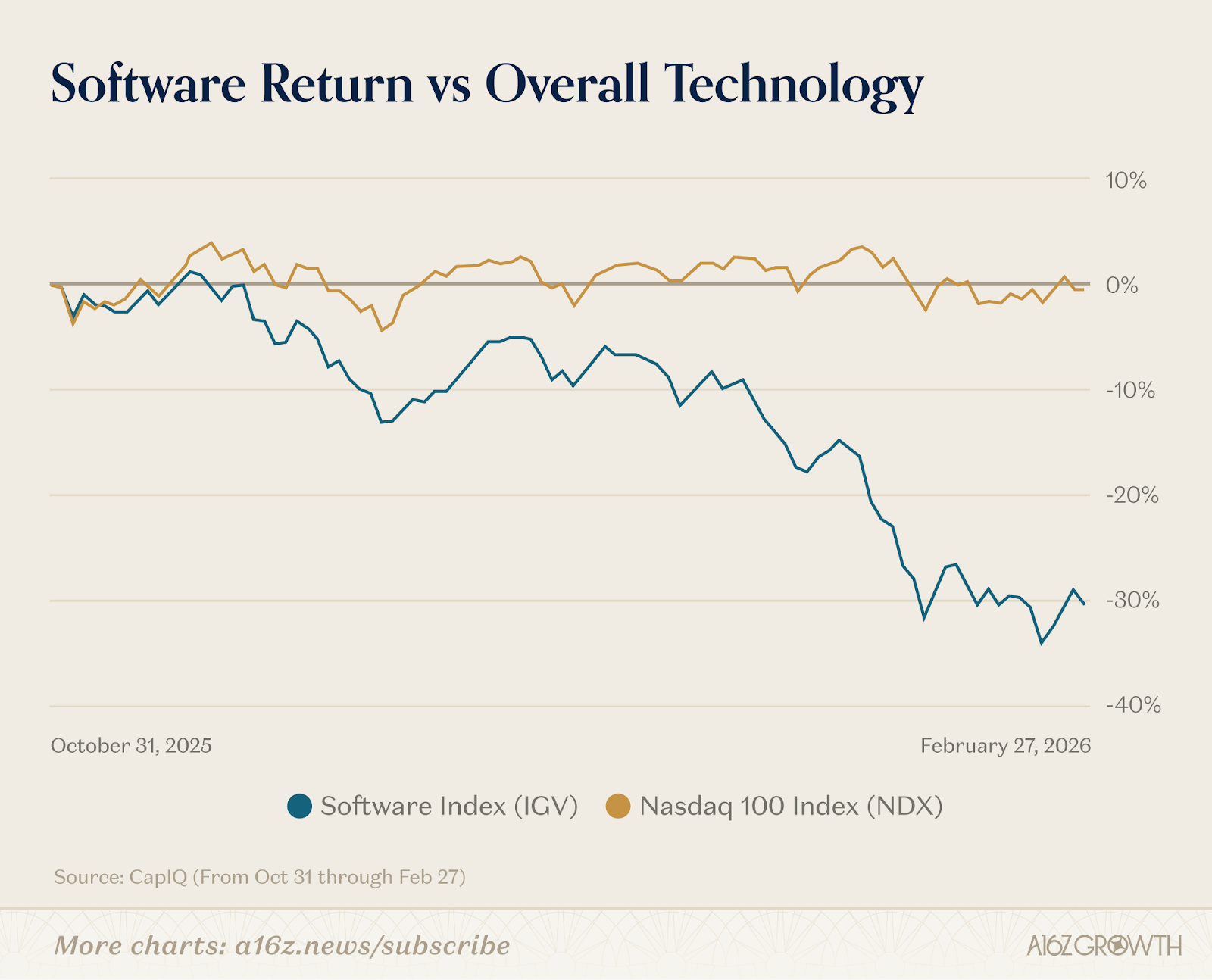
So how can a16z be so bullish?
Their argument rests on Hamilton Helmer’s Seven Powers framework. The moats that made software companies valuable (e.g., scale, network effects, cornered resources, process power) don’t disappear when code gets cheaper. In fact, most of them get stronger. The hard part of software was never the code. It was the ecosystem around it: the data, the integrations, the workflows, the institutional knowledge baked into how organizations actually use the product.
AI makes the code cheaper. It doesn’t make the creation of the ecosystem cheaper. It actually makes it more important to get right, because without it, you’re much more likely to get vibe coded slop and silos. The one moat that does weaken? Switching costs. And that’s worth paying attention to because the vendors relying primarily on lock-in rather than value are the ones who should be worried.
Aaron Levie echoed this from a different angle, responding to Lenny Rachitsky’s / TrueUp’s data showing engineering job openings at a 3+ year high:
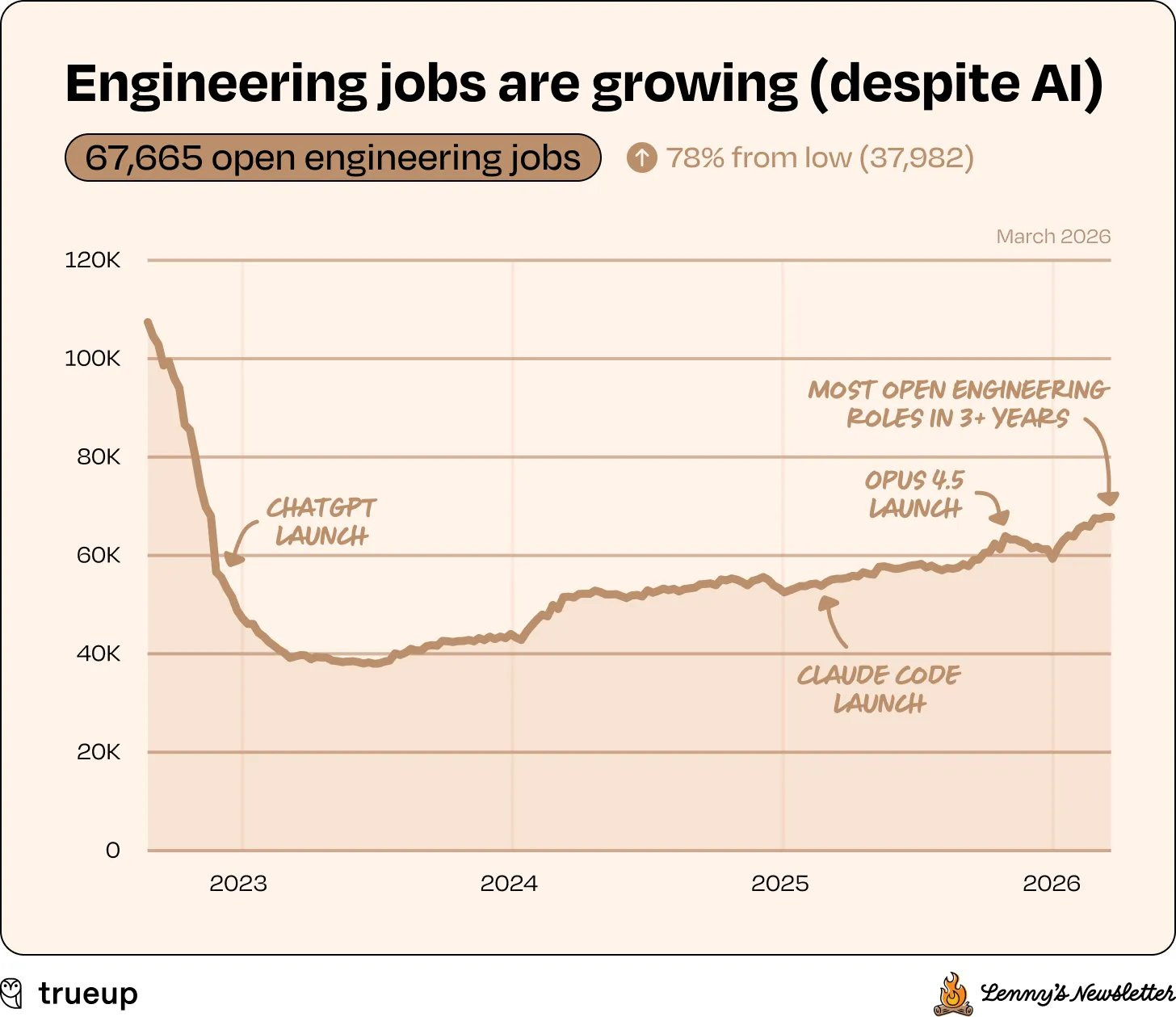
“We’re going to start to use software for all new things in the economy because it’s incrementally cheaper to produce. Marketing teams at big companies will have engineers helping to automate workflows. Engineers in life sciences and healthcare will automate research. Small businesses will hire engineers for the first time to build better digital experiences.”
This is Jevons paradox in action. When something gets cheaper to produce, demand explodes. And the data supports it:
- 40% of enterprise applications will include task-specific AI agents by end of 2026, up from less than 5% in 2025 (Gartner)
- Netlify CEO Matt Biilmann revealed on the a16z podcast that the platform is seeing 16,000 daily signups (5x last year’s rate) and 96% aren’t coming from developer tools. They’re everyday people building React apps through ChatGPT and then looking for somewhere to put them
- Lovable, a platform where you describe an app in plain English and get a working full-stack web application, hit $100M ARR in 8 months, making it one of the fastest-growing SaaS companies ever.
More software is coming. A lot more. The question is what all that software connects to and how it drives value. The code gets written in minutes, then sits in review queues, creates merge conflicts, introduces subtle bugs, and fragments into disconnected silos. Sound familiar? It’s the same wall I hit with my portfolio tracker, just playing out across thousands of teams.
And there’s another bottleneck nobody’s measuring yet: when developers can build anything in hours, the people who define and design what to build become the constraint. Product managers, designers, and domain experts can’t spec fast enough to keep up with the creation capacity.
Context Is the New Code
Let’s go back to my portfolio tracking app and the roadmap app my colleague is creating, both running on localhost. How did we solve that problem?
- Step 1 was to switch my local Supabase database instance to a Databricks Lakebase connection, which created a way to centralize the data via syncing the change data capture updates to our organization’s datalakehouse. But that didn’t solve the deployment problem.
- Step 2 was deploying my app as a Databricks App which made it accessible and securable with my company’s SSO and dramatically improved performance.
- Step 3 is waiting for my colleague to do the same thing (you know who you are 🙂 so I can pull the data from his app into mine to establish the appropriate cross-references needed to provide high-level rollups backed by epics and user story data.
And these are simple CRUD apps. They don’t have specialized functionality or sophisticated domain features. And yet we’re feeling the challenges that come from disconnected software even at this small scale. Imagine the same fragmentation playing out across scientific workflows, clinical data, and regulatory submissions.
Platforms like Vercel, Replit, and Lovable solve creation and deployment. Databricks, Snowflake, and Salesforce go further by enabling a governed data layer, authentication, and the infrastructure to keep apps from becoming silos. That’s real progress, and it’s what saved my portfolio tracker. But even when that infrastructure is used well, the platform doesn’t understand your domain context. And haven’t you heard? Gartner declared 2026 “The Year of Context.” Joking aside, at Gartner’s D&A Summit, analysts noted that while 4 out of 5 organizations have now deployed AI, only a fraction are seeing measurable ROI. The gap is context.
At Anthropic’s recent Opus 4.6 hackathon, 13,000 people applied and 500 got in, most of them professional developers. A California attorney took first place by building a permit-processing app in six days. He won because he understood housing law, not JavaScript. He had important context.
This is the shift. When creation is cheap, the scarce resource flips from code to context, governance, and domain intelligence that make the code useful, and more broadly the ecosystem.
The Ecosystem
What about regulated and highly sophisticated domain-specific verticals where the substrate needs to understand not just data governance but domain context: what an assay is, what GxP compliance requires, what a compound structure means, how a multispecific antibody format should be represented? That’s a harder question.
Some vendors are responding to this moment by building higher walls, pulling everything inside their platform, migrating off open ecosystems, and creating agents that only work within their proprietary environment. That’s the “ecosystem as a prison” move. But as a16z correctly pointed out, switching costs are weakening. The vendors relying on lock-in rather than value are the most vulnerable precisely when their customers are gaining the ability to build alternatives.
The harder and more interesting question is: who provides the open, governed, domain-aware substrate that all this newly created software can exist within and connect to? The scientific interfaces, ontologies, compliance frameworks, and domain semantics that make a vibe-coded tool actually meaningful in context. This is the type of ecosystem that’s needed going forward.
In my first Substack post, I wrote about how life sciences is a particularly strong example of this challenge because:
- The work is physical
- The interfaces are specialized
- The ecosystem is fragmented
- Insights emerge through integrations
- The stakes and regulation are high
A scientist who vibe-codes an analysis tool needs more than a place to deploy it. They need the workflow orchestration to drive automation, the data models to represent scientific objects precisely, the structured context so AI can reason over known relationships, and the integrations so their results don’t become another island. That’s what a domain ecosystem actually provides.
What Wins
I believe a platform ecosystem that enables an expansion from FAIR data to FAIR apps is what will win in most sophisticated vertical industries. This is because it leans in to where software development is headed rather than fighting against it. Until recently the focus on mitigating software complexity has been heavily focused in data because of its rapid proliferation and disconnected nature. That’s still true but these characteristics are now transferring further into the application layer, creating a multiplicative effect on the problem (X data silos * Y apps). Which means you now need to apply some of the same data principles to apps, particularly because of how easy, and addictive, it’s becoming to create them.
I have found that once people experience the empowerment and even joy that comes from vibe-coding something they’ve envisioned, there’s no putting that genie back in its box, nor is it advantageous to do so.
The platforms that lean into this and make themselves the ecosystem their customers’ apps are built on rather than trying to build all the apps themselves will capture the next era. Whether it’s a portfolio tracker or an antibody analysis tool, the winning move is to make it more valuable, not to replace it.